
楔子
其实市面上有很多关于卡顿优化相关的文章,从入行没多久就接触到了YY大神的iOS 保持界面流畅的技巧延伸到现在百花齐放的各路优化技巧,但是万变不离其宗的原理还是减少CPU和GPU的工作量,让这二位兄弟不用处理高强度的任务。
卡顿产生的原因
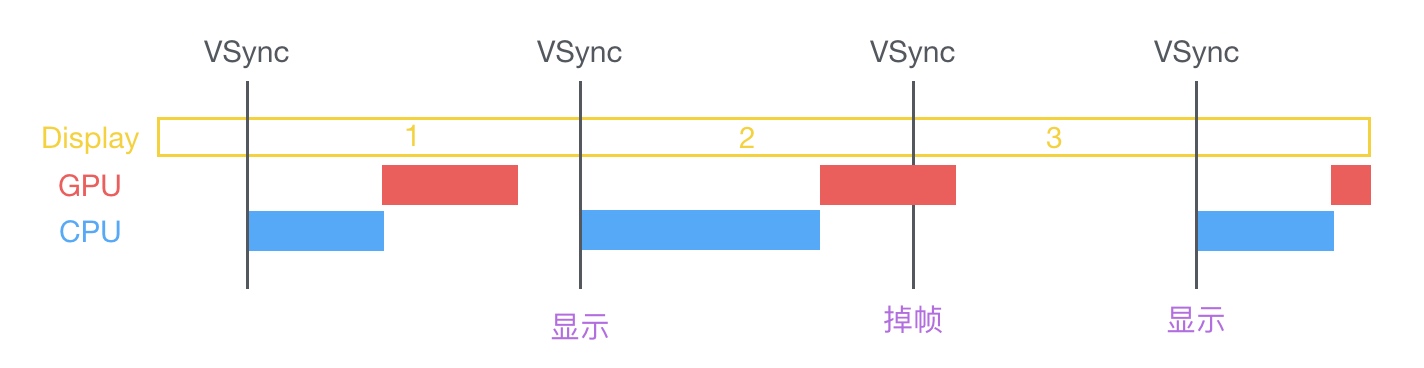
当主线程启动时会先有CPU处理好需要显示的数据,然后交付给GPU,然后GPU通过合成、渲染等操作将处理结果提交到帧缓存中,当垂直同步信号到达时将处理结果显示到屏幕上。每个垂直同步信号到达的间隔约为16.67ms(1秒60帧),如果在CPU和GPU在垂直同步信号到达直接就交付处理结果到帧缓存中则不会产生卡顿,而当CPU和GPU两者处理时间大于16.67ms则会出线掉帧的情况,如上图所示,第二帧处理的时间过长,垂直同步信号已经到达GPU依然没有将数据提交到帧缓存中,则该次计算的处理结果将在下一个垂直同步信号结果到达时再显示到屏幕上,这就是卡顿的原因。
所以,不论是CPU处理时间过长还是GPU处理时间过长都会出现卡顿的情况,如何给这二位兄弟减负就是解决卡顿的方案。
Core Animation
Pipeline
为什么要介绍Core Animation?首先咱不要被他的名字误解认为他是个做动画的,他的职责是将可视内容划分视图层次结构,然后交付给GPU进行加速渲染。
以下为Core Animation的流程图(来自WWDC 2014 Session 419)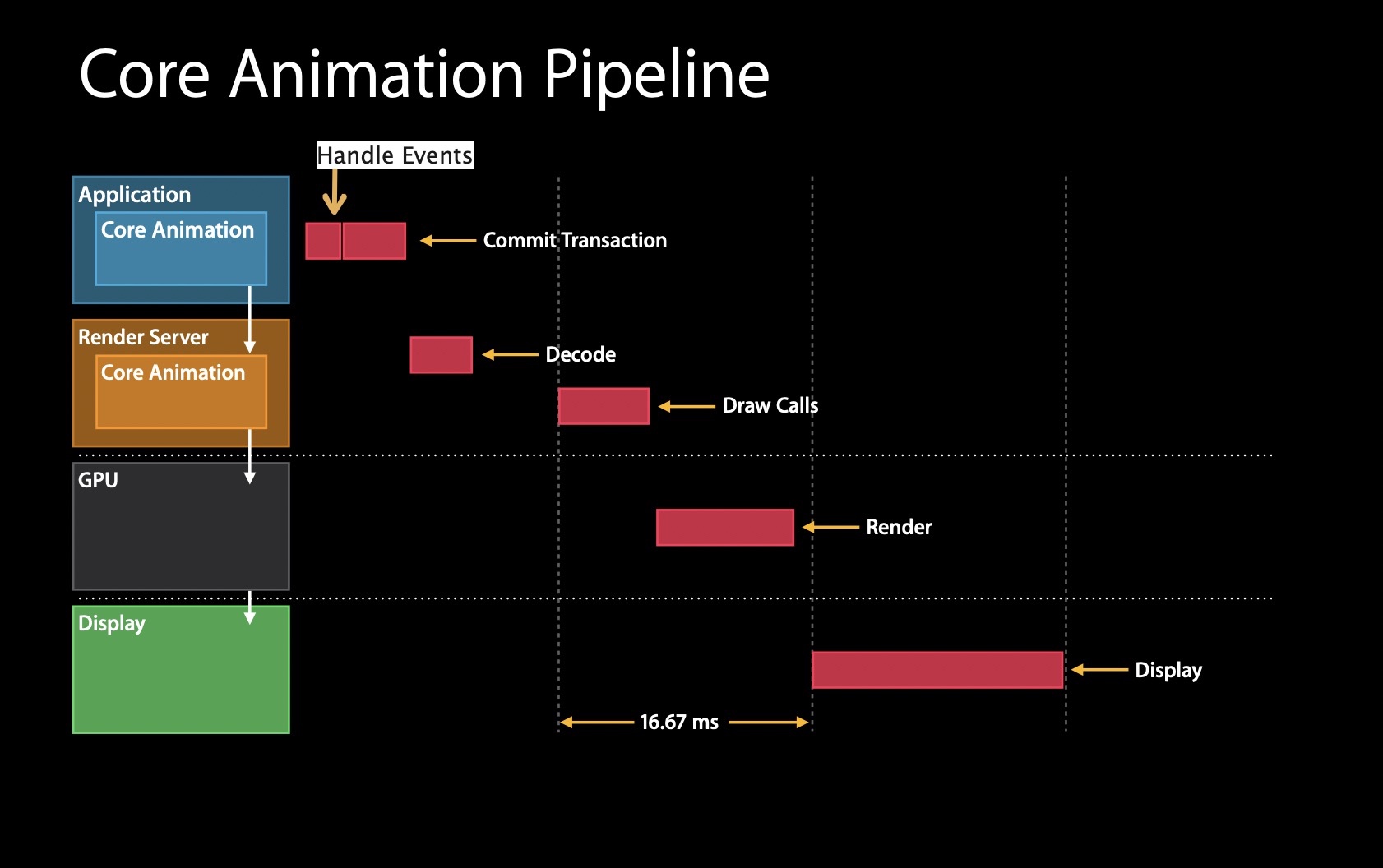
流程如下:
1、Application接收到需要更新视图层级的通知,这个阶段为事务提交阶段
2、事务提交阶段结束时,视图层级结构将被编码并发送到渲染服务器
3、渲染服务器对步骤2发送过来的数据包进行解码
4、渲染服务器等待下一次同步时机以等待GPU渲染之后的结果(调用OpenGL ES或者Metal)
5、当视图资源可用且审查完毕时即可让GPU开始渲染工作,这些工作都应该在下一个同步信号到达之前完成,因为需要切换帧缓冲区并向用户显示视图结构
6、显示至屏幕
Commit Transaction
事务提交阶段是开发人员最长接触的地方,也是影响App渲染性能的最大因素
如上图所示,事务提交分为四个阶段:
1、布局阶段,用于设置视图。这个阶段的主要操作是调用addsubview以及数据填充,该阶段的所有操作都都应该是轻量级的,耗时过长必定会造成丢帧。CPU和I/O操作在该阶段是受限制的。
2、绘制阶段,用于绘制视图。重写了drawrect或者存在字符串绘制的时候会在这个阶段进行绘制,该阶段利用Core Graphics进行渲染,因此我们应该最大程度的减少Core Graphics的工作量,以避免在此阶段造成较多的性能损耗。
3、准备提交阶段,此阶段会执行Core Animation的一些其他工作。该阶段主要是图片解码和图像转换,一些常见的图片格式的解码过程是在这个阶段进行的,但是往往可能会出现GPU不支持的图像格式,即不支持硬编码,就需要进行转换格式,转换格式又是一个耗时的操作,所以要避免一些非常规的图片格式。
4、提交阶段,将layers打包并发送至渲染服务器。看起来打个包提交至渲染服务器这个操作很简单,实际上这是一个递归操作,当一个页面的层级越深越复杂,所带来的资源消耗也是蹭蹭蹭的往上涨,因此尽量保证图层树平整。
优化方案
从Core Animation的流程图和Commit Transaction的步骤我们对界面的渲染流程有了大概的一个了解,那么如果碰到一个丢帧的界面该从什么地方开始着手优化呢?
根据Commit Transaction的四个阶段我们应该遵循这个渲染的顺序寻找性能损耗过高的操作。
布局阶段
这个阶段CPU需要计算视图的frame、约束、层级等,这里会有遍历layerSubview和layoutSubLayers的操作,所以这一步我们应该:
- 在frame确认不会变动之后再去设置视图的frame,而不是随心所欲的代码块开始的时候设置一遍,然后在代码块结束的时候再设置一遍。
- 视图层级尽可能的设计简单一些,嵌套的越深,CPU需要损耗的资源也就越多
- 善用Auto Layout,在iOS12之前很多约束变化时都会重新创建一个计算引擎 NSISEnginer 将约束关系重新加进来,然后重新计算。结果就是,涉及到的约束关系变多时,新的计算引擎需要重新计算,最终导致计算量呈指数级增加。而iOS12之后苹果对Auto Layout进行了优化,使其具有与手动设置frame相媲美的高性能,但是这也不是你能随心所欲的使用它的理由,约束多一个,计算就会多一次,所以在使用Auto Layout时请尽可能的减少约束的设置,比如你设置了某控件的top和bottom,那么height就没有必要再去设置一遍了。
绘制阶段
- 如果重写了drawrect方法,请尽可能轻量的去完成重写方法
- 如果没有必要,请减少对Core Graphics的操作
准备提交阶段
一般这个阶段处理的都是图片解码相关的操作
尽量使用32bit格式的图片(前面3个8bit分别代表R/G/B三原色,最后8bit代表透明度),如果不是32bit的图片则会调度CPU去将图片进行格式转换
提交阶段
到这个阶段以及不是我们的能干预的了,因为这个阶段会递归取出层级结构中的视图,所以为了避免该阶段的时间复杂度变高,请尽量保证视图层级的平整。
小结
尽量保证视图结构的平整,frame确定之后再设置,图片尽量使用32bit格式。满足以上三点基本上就能保证Core Animation Commit Transaction的流畅了。
有的同学可能会觉得这些细微的耗时操作可能并不会影响到程序的流畅性,但是要在16.67ms完成这些工作,可能你这一个0.1ms的操作就是压死骆驼的最后一根稻草。
CPU
在卡顿的原因中我们了解到当CPU或者GPU超负荷工作时会产生掉帧的情况,而刚刚介绍的Core Animation则是串通CPU与GPU的过程,要在这16.67ms完成一次显示操作仅仅针对Core Animation做优化是远远不够的,一般CPU的工作是造成性能损耗的大头,做好对CPU资源的合理分配则是性能优化的重头戏。
耗时的操作及优化方案
通常一个App的数据展示页都是由UITableView/UICollectionView作为载体的,数据从服务端拉取。假设我们的app有一个结构有些复杂的列表页,从服务端获取数据后直接在heightForRow中计算cell的高度,那么卡顿和丢帧就随之而来了。
创建对象
通常一个复杂的页面都会有很多的控件对象存在,控件越多,开销就越大。如果使用的是Storyboard创建的视图对象的话所带来的资源消耗会比纯代码创建的高出很多。
可以适当是使用懒加载,而不是在viewDidLoad时一次性加载出所有的控件,这里有一个典型的例子就是tabbar加载时可以只加载首屏出现的第一个viewController,别的tab可以进行延迟加载。
不涉及触摸事件的控件可以使用CALayer创建,相比UIView,它更为轻量,但是AutoLayout只支持对UIView进行操作,这可真是让人烦恼的问题。
布局计算
视图布局的计算是App中最为常见的消耗CPU资源的地方,也经常会出现对一个控件进行多次设置frame的操作。
我们在从服务端获取了之后先别着急着reloadData,可以开辟一个新的线程进行控件布局计算,布局计算完毕后回到主线程reloadData。
下面是YYKit中的一个例子:
1 | - (void)loadData{ |
图片的解码与转码
当使用UIImageView设置图片且addSubview操作发生时,这时候才会对图片进行解码,这一步是发生在主线程的,但是可以在子线程中把图片绘制到CGBitmapContext中,然后从Bitmap直接创建图片。
在Core Animation的流程中我们提到了当GPU有不能识别的图片格式时会让CPU对该图片进行转换的操作,如果从服务端获取的图片并不是32bit的图片则很有可能造成性能损耗。
从服务端加载加来的图片为二进制数据Data Buffer,需要decode放到image Buffer才能被渲染,而常用的SDWebImage和YYImage等著名开源图片框架都是通过子线程异步解码绘制位图,然后回到主线程进行操作,和预排版有异曲同工之处。
1 | - (void)URLSession:(NSURLSession *)session dataTask:(NSURLSessionDataTask *)dataTask didReceiveData:(NSData *)data { |
iconfont (只适用于使用了iconfont的App)
iconfont是alibaba开源的矢量图标库,提供矢量图标下载、在线存储、格式转换等功能。
iconfont可以直接作为一个字体来使用,也能转换为图片进行使用。当作为字体使用时仅仅触发文本渲染,和正常的普通文本没什么实质性的差别,但使用不当也可能造成性能上的损耗。
首先,当iconfont转换成图片展示时也会触发图片的解码/转码,而且在调用转成图片的方法时会调用Core Graphics进行图片绘制也会带来一定的开销,而且在之前介绍的Core Animation的流程中也不太建议使用Core Graphics进行图片绘制,所以如果没有特别的必要,请尽量使用文本的方式渲染出你想要使用的iconfont。
富文本渲染
富文本渲染是一个痛点,从文本转为富文本就会产生一定的开销,然后进行富文本渲染时又会带来一定的开销。
目前比较成熟的解决方案是使用成熟的三方富文本库或者使用Texture进行异步绘制。
小结
上面所提到的问题及解决方案并不能完全覆盖所有App会遇到的卡顿场景,可能在部分App中出现了多个嵌套循环的代码,或者加载某个三方SDK时会大量占用CPU资源,上述的问题仅仅是做一个抛砖引玉,因为面对问题还得对症下药。
GPU
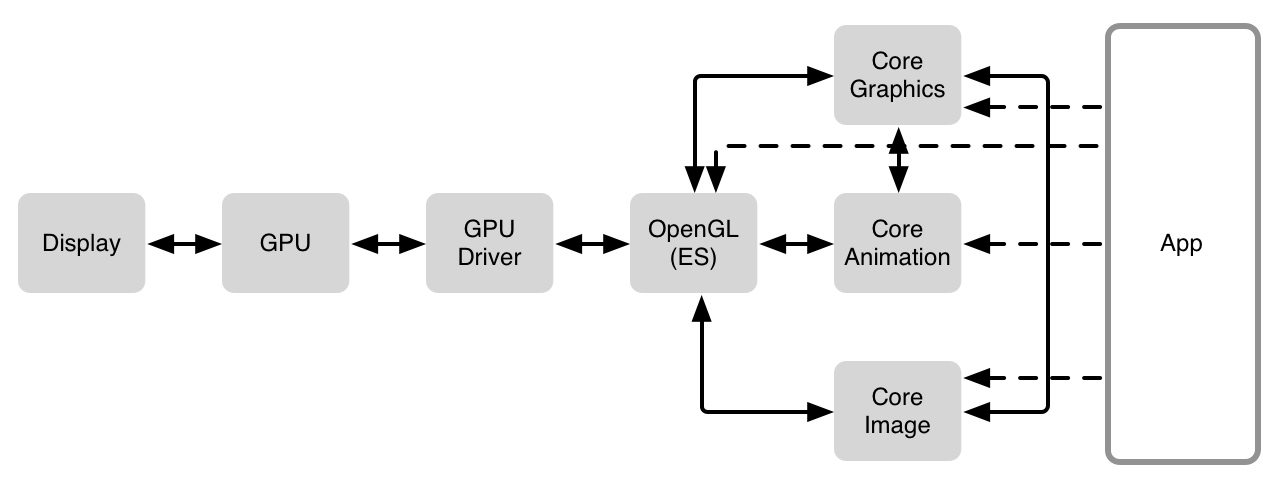
由上图所示,一台iOS设备的CPU和GPU由总线进行连接,也可能通过Core Animation、Open GL/Metal进行任务调度。为了让像素能够显示到屏幕上面,有一些工作需要派发给CPU,然后将数据传输给GPU,再对数据进行处理,最后显示到屏幕上面,这个阶段就是由Core Graphics进行数据传输。
CPU善于计算而现今的GPU被高度优化设计,非常善于图像处理的工作,分工明确,用通俗的话说就是男女搭配干活不累。
在介绍GPU相关工作之前有一些相关内容需要先行介绍一哈
像素
一块屏幕上显示的东西都是由N个像素拼凑而来的,而一个像素都由四个部分组成,那就是三原色(R,G,B)和透明度(A),其实跟之前介绍的bitmap一致也是32bit。
iOS和OS X上面的最通常的文件格式是32 bits-per-pixel (bpp),8 bits-per-component (bpc),alpha会被预先计算进去。在内存里面像这个样子:
1 | A R G B A R G B A R G B |
这种格式通常被称为ARGB,每个像素占4个字节。一个像素的颜色计算就是通过A的值分别乘上R/G/B的值,例如ARGB的值分别是255、240、99、24,这时将alpha设置为0.33,那么这个色值的ARGB结果就是84、80、33、8。
还有一种格式是xRGB,看名字也能知道这是个忽略alpha的格式,内存结构如下:
1 | x R G B x R G B x R G B |
内存布局和ARGB的一致,那么问题来了,既然alpha不存在为什么还有使用相同的结构?把这个没有字节从内存中干掉不是能节省25%的空间吗?
这就牵扯到内存对齐的问题了,CPU在读取内存不对齐的数据时会将内存进行位移计算,而且在处理ARGB的32位时又不需要去计算偏移量。使用这样的内存布局虽然浪费了一些不必要的空间,但是保证了内存的一致性,并且节省了CPU一些不必要的开销。
Core Graphics处理RGB数据时会将alpha的值放到最后变成RGBA和RGBx(RGB已经预先乘以alpha的格式)
图片格式
目前市面流行的主流图片格式为JPEG和PNG,做个简单的介绍
JPEG
JPEG数据要变成像素格式得经过一个非常复杂的过程,如果感兴趣的话可以去google一下,反正过程很复杂,然后导致jpeg图片显示到屏幕上会有一点延迟,因为CPU需要解压图片,如果每一个Cell都需要加载JPEG图片的话就会导致滑动不是那么流畅。
那么为什么还要用这种格式的图呢?因为JPEG使用有损压缩方式去除冗余的图像和彩色数据,在获得极高的压缩率的同时能展现十分丰富生动的图像,即可以用较少的磁盘空间得到较好的图片质量,但这仅仅适用于照片,如果你从网页上截图,JPEG的压缩效率就会变得很低,甚至图片效果发生了改变。
PNG
PNG与JPEG相反,采用无损压缩,保存为PNG格式后再打开,所有的像素属于和原始数据完全相同,也正是因为这个限制PNG的压缩效果没有JPEG那么好。
有弊则有利,PNG在解码效率方面会比JPEG强上许多,而且PNG支持压缩有alpha或是没有alpha通道的RGB像素,这也就是为什么他适合在app中使用的原因。
还有一点Xcode对PNG格式的图片进行了优化,在对图片压缩时将文件格式转换,在iOS系统读取的时候处理速度会比常规的PNG图片速率更快。Xcode对它们进行了更改,以使iOS使用更有效的解压缩算法,该算法不适用于常规PNG。值得注意的要点是它会更改像素布局。正如我们在 像素 中提到的,有很多方法可以表示RGB数据,如果格式不是iOS图形系统所需要的格式,则需要为每个像素做偏移计算。
图像合成
刚刚已经介绍了像素的基本概念,我们的App的界面通常是由不同的位图合成之后再显示到屏幕上,这背后究竟都隐藏着哪些不为人知的操作?
假设有两个大小一致且像素对齐的图层分别为图层A和图层B,B覆盖在A上,GPU要计算每个像素合成后的RGB值,这里使用的模式为普通的覆盖模式,那么最后的颜色就是通过下面的公式所计算出来的:
1 | R = S + D * (1 - Sa) |
最后的结果是通过源的颜色(图层B)加目标颜色(图层A) 乘以(1 - 源色的透明度),公式里面所有的颜色就假定已经预先乘以了他们的透明度。
看起来这个公式并不复杂,但是这只是合成了一个像素而已,GPU需要将两个图层中所有的像素都进行合成,然后你可以打开Xcode中的Debug View Hierarchy看看你的App到底有多少层就知道GPU被摧残的有多惨了。
透明度
当顶层的图层完全不透明时,最终的颜色就和顶层的一样,这样可以省去GPU的很多工作,因为GPU直接复制图层的像素来使用而不用去做合成计算。但是GPU可不知道你所做出的图层的像素是不是透明的,因为CALayer是通过咱们程序猿来操作的,如果opaque的值为true,那么CPU则不会做任何合成计算。
Xcode已经提供了Color Blended Layers功能,在模拟器-Debug-Color Blended Layers。
如果你确定某个控件是一定不透明的,那么麻烦你给他设置成opaque = true
UIView, UILabel, UIImageView, UITextView的默认值是true,但UIButton,UITextField等子类的默认值都是false。
像素对齐
上述的理论都是建立在像素完美对齐的情况下,这种情况使用一个相对简单的公式即可完成计算。
造成像素不对齐的原因:
1、缩放:当一个图层放大或者缩小时,图层的像素和屏幕像素排列的就会产生不一致
2、边缘不对齐:图层的起始坐标和屏幕的起始坐标不一致
当像素不对齐时,GPU需要做一些额外的计算将图层上的像素混合起来,而像素对齐时GPU的负担就没有那么重了。
Xcode提供了Color Misaligned Images功能,当UIView的frame像素不对齐显示紫色;当图片的像素大小与控件的大小不一致而导致需要缩放时,显示黄色。
离屏渲染
为什么会有离屏渲染
离屏渲染是指GPU在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染。当某些图层不能直接绘制到屏幕上必须进行预合成,这就是为什么会存在离屏渲染的原因。
离屏渲染为什么会带来性能问题
首先离屏渲染会创建新的缓冲区,然后渲染到屏幕缓冲区再将结果渲染回帧缓冲区,这个缓冲区创建和缓冲区切换会带来高昂的代价,如果在16.67ms内没有完成渲染工作,那么就会出现掉帧的现象。
产生离屏渲染的原因
- cornerRadius和masksToBounds一起使用绘制圆角的时候会触发离屏渲染
- 设置了mask
- 设置了shadow
- 光栅化
如何优化
圆角绘制问题网上有不少的答案,首先需要声明的一点是在iOS 9及更高的系统版本里使用UIImageView且图片为png格式设置圆角已经不会触发离屏渲染了,而其他控件设置圆角依然会触发离屏渲染。其次,如果当一个页面只有零星几个控件需要设置圆角的话也不建议采取优化的方式去做,直接设置圆角问题也不大。
目前有以下几个优化方案:
- 让UI同学直接给出圆角图片,这个方案最省心,但适用场景有限
- 使用UIBezierPath和Core Graphics绘制圆角,在上文提到了不建议使用Core Graphics去绘制图形,而且要做圆角优化的地方肯定有大量的控件存在,这样会增大CPU的负荷,可以在CPU空闲的时候在子线程进行预合成。
- 使用CAShapeLayer和UIBezierPath绘制圆角
1 | func roundCorners(corners: UIRectCorner, radius: CGFloat) { |
CAShapeLayer使用了硬件加速,绘制同一图形会比用Core Graphics快很多,但设置mask依然会触发离屏渲染。
4.通过混合图层,在要添加圆角的视图上再叠加一个部分透明的视图,只对圆角部分进行遮挡,该方法耍了个小聪明,但是上面透明度的问题在这里也就显现的淋漓尽致了。
以上几种解决方案都尺有所短寸有所长,怎么去优化就按需分配了。
总结
本文从Core Animation开始切入一直到屏幕显示这个流程分析了可能产生性能问题的原因。问题的出现大多数情况都是CPU负载过高或是GPU使用不当造成的,我们可以使用Xcode提供的Instruments中的各种工具定位性能问题,然后分析出解决问题的办法,平衡CPU的任务,合理使用GPU就能顺利解决性能问题。
文档参考
Getting Pixels onto the Screen
iOS 保持界面流畅的技巧
WWDC2014 419_advanced_graphics_and_animation_performance